Trojan Source Code (Can we trust open-source anymore?)
Last year, I overheard my boyfriend listening to a podcast that talks about the Trojan Source Code. I got interested and read the paper. Here is a beginner friendly explanation if you don’t want to read it (but I cannot see why).
First, let’s have some fun!
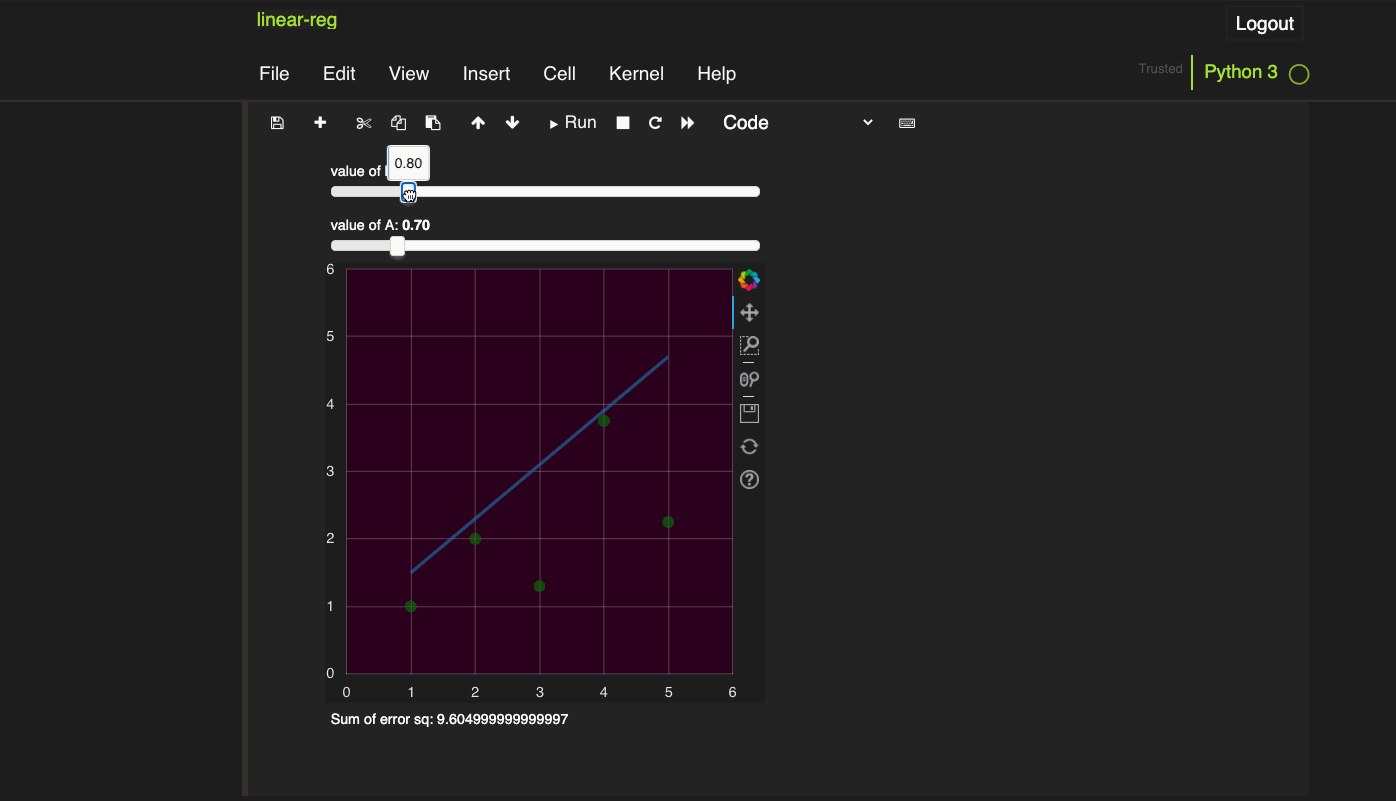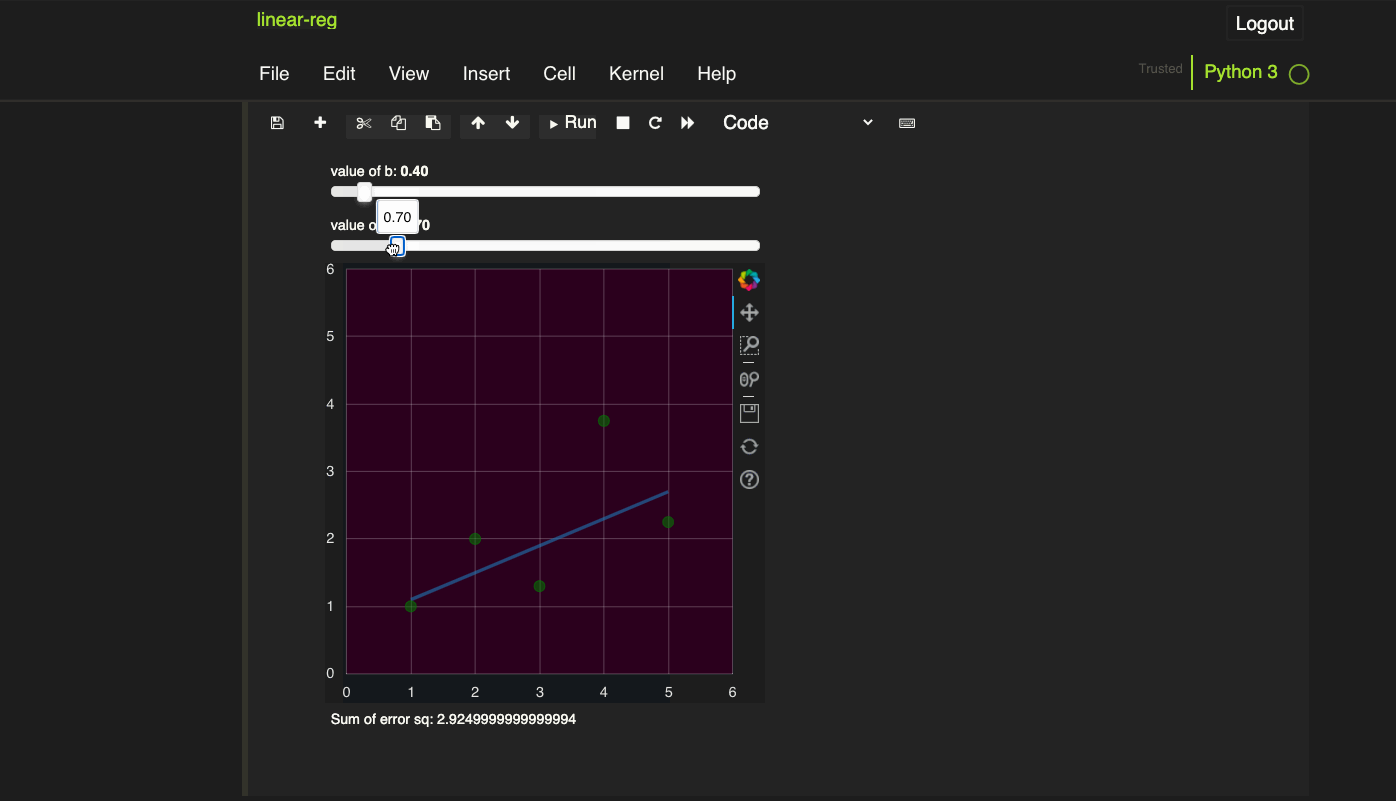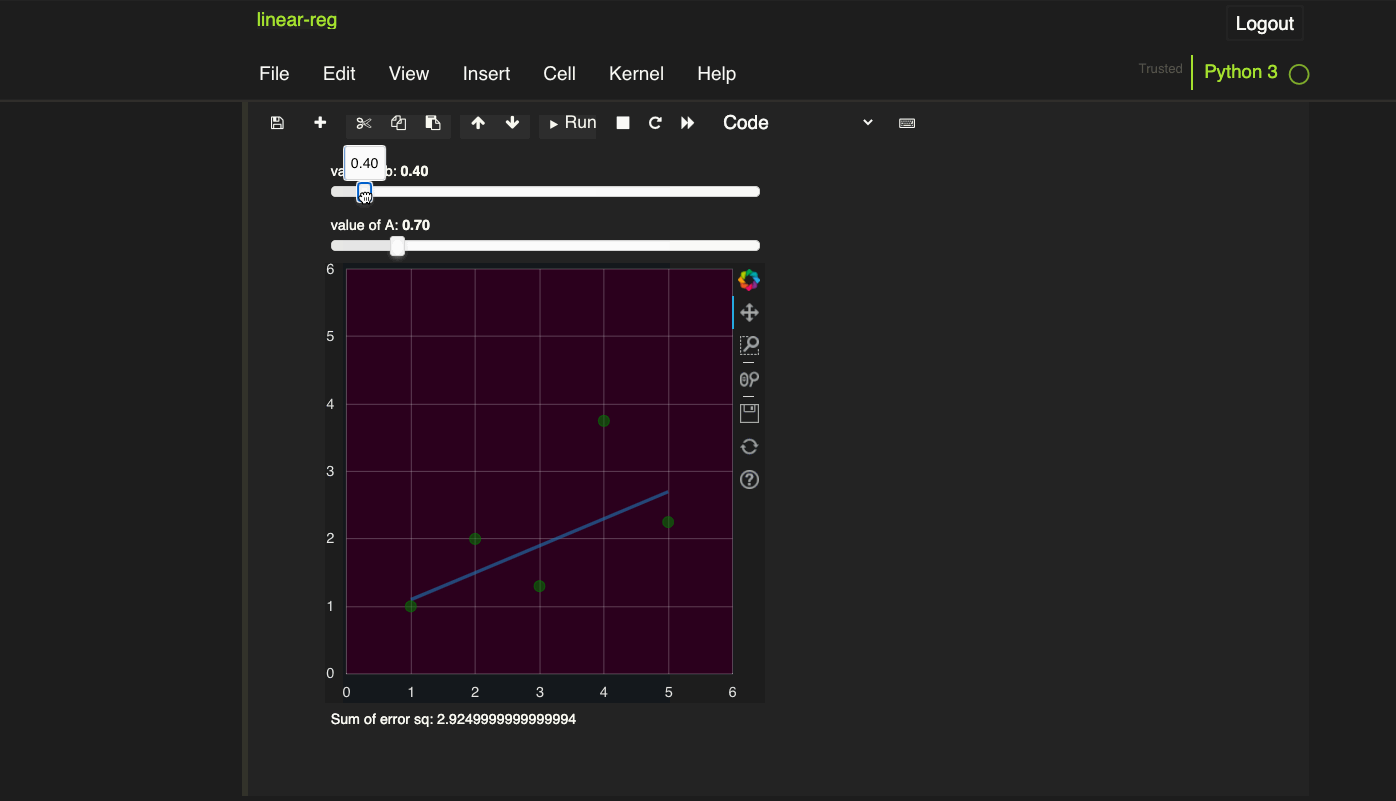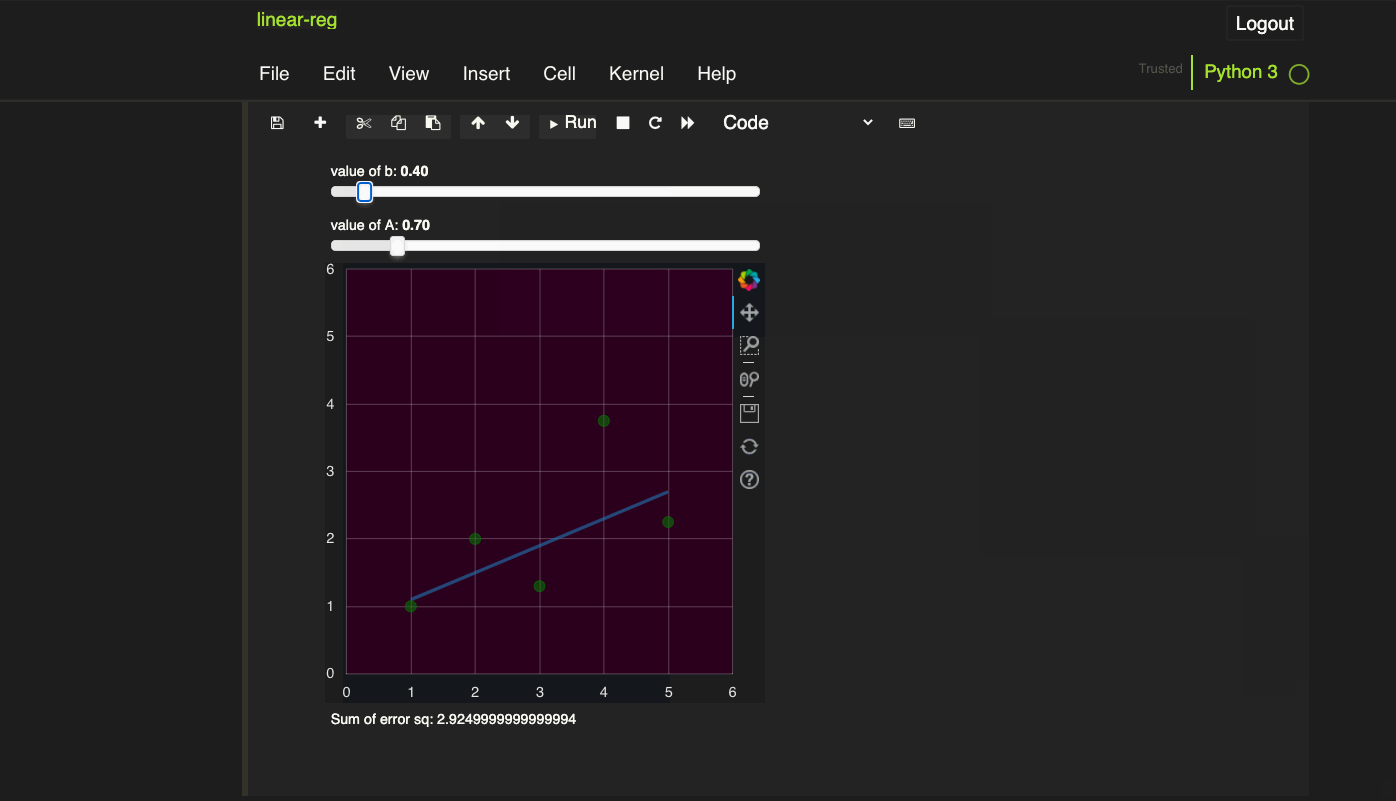
Open the online Python console here and try running the following code:
hello = "Hello world"
world = hello
print(world)
It is a standard “Hello world” right? How about this:
hello = "Hello world"
world = hello
print(world)
Wait! They LOOK the same!
Yes my friend, you are right. They look the same but are NOT the same.
Unicode! Uηicσժe!! Ⓤⓝⓘⓒⓞⓓⓔ!!!
We all know unicode is a bit wacky. But can you imagine a world that does not support unicode?
Unicode started as an attempt to make computer characters display all writing systems in the world. I benefit from it when I was a kid, learning how to use a computer at school. Like all “good kids” I will secretly open Netscape to browse websites. At that time, no one really care about the encoding when designing website. Sometimes, I would browse a website in Chinese but was displayed in random symbols. Then I know it’s time to change the encoding.
The most common unicode encoding is UTF-8, but there are many. For example, we use Big-5 for Chinese characters.
Our favourite emojis 💖😃🧸 are mostly added in 2014, and there will be more coming.
Bidirectional characters
Since unicode are designed to handle all writing system, and some writing systems (like Arabic and Hebrew) are reading and writing form right to left, oppose to left to right, what we English speakers are used to, there needs to be a way to tell the computer to “read” and display the characters from right to left. That way, is a set of “invisible” characters that indicate the directions of the text - Bidirectional characters.
Using bidirectional characters where it is not suppose to be, like codes, then it is not just weird, but it can cause more harm than that.
Trojan Source Code
We all know the story about the Trojan Horse, hiding solders in a huge horse that was suppose to be the gift. This is what Trojan Source Code is like, hiding in the source code. In the paper the researchers listed 3 types of Trojan Source Code:
1) Early returns
By hiding the bidirectional characters and return statement in the comment, what appear to be harmless comment can force a function end early and leave out codes that needed to be executed.

2) Commenting-out
It is common to have comments alongside the code to help readability. By strategically adding bidirectional characters, what appear to be code that are executable will actually be a part of the comment when executed. Using this can make the code behave not as expected.

3) Stretched strings
Similar to commenting-out, what appear to be not included in a string can be “put” inside the string with bidirectional characters and “change” the behaviour of the code.

Besides there Trojan Source Code there are also similar exploitation with unicode:
1) Invisible character
Hiding invisible characters can be easily used to change behaviour of the code. Like replacing variable names or strings etc.
2) Homoglyphs
Similarly, homoglyphs (which means characters that looks the same but aren’t the same) can be used to replace function names so the unexpected one will be executed instead.

Should we be worried?
For the list of what works in Python you can see here at the GitHub repo. You are welcome to try those Trojan Source Code and see if they works on newer versions of Python.
For my personal opinion, the piece of advice I would give to other Pythonistas is that, use a editor with good syntax highlight or that will warn you if there’s hidden characters (GitHub will give you a warning if the code file contains bidirectional characters). Keep a good habit of linting your code (Pylint is a good choice, it will also give you warning if it “sees” hidden characters) and double check before running any code, especially those that copy and paste form the internet.
That’s only the beginning
As someone who works in open-source, I am always aware of the security of our work. We don’t want to accidentally spread malicious code and that harm the trust on the open-source software as a whole. There are more security issue that people keep finding and warning others, and we should all be aware.
I would like to thank the researchers who publish their findings. If you would like to know more, make sure you check out their website: https://trojansource.codes/
Here is my presentation slides: